DeepKe开源框架实战1:从环境配置到项目运行的踩坑之路
Posted 
DeepKE实战探索

By
6 min read
DeepKe开源框架实战1:从环境配置到项目运行的踩坑之路
DeepKE-LLM 是一个基于大型语言模型的知识抽取工具包,本文记录了我在实践 CodeKGC 项目时的探索历程和解决方案。
前言
在知识图谱构建领域,基于代码语言模型的方法越来越受到关注。DeepKE 项目中的 CodeKGC 模块提供了一种新颖的解决方案,通过将知识抽取任务转化为代码生成任务来实现。本文将详细记录我在实践这个项目时的经验,希望能为后来者提供参考。
项目概述
CodeKGC 是一个基于代码语言模型的知识图谱构建工具,其核心思想是将知识抽取转换为代码生成任务。项目位于 DeepKE 的 example/llm/CodeKGC 目录下。
项目特点
- 创新的方法论
- 使用代码语言模型进行知识抽取
- 将关系抽取转化为代码生成
- 支持灵活的模式定义
- 完整的工具链
- 提供数据预处理脚本
- 集成 OpenAI API 调用
- 支持自定义模式扩展
环境配置详解
依赖安装过程
在配置过程中,我遇到了几个典型问题,这里详细记录解决方案:
1. EasyInstruct 安装问题
首次运行时遇到模块缺失:
1
ModuleNotFoundError: No module named 'easyinstruct'
解决步骤:
- 尝试直接安装:
1
pip install git+https://github.com/zjunlp/EasyInstruct@main - 遇到编码问题后,采用本地安装方案:
1 2
git clone https://github.com/zjunlp/EasyInstruct.git cd EasyInstruct - 修改
setup.py文件,解决编码问题:1 2 3 4
# 将 with open("README.md", "r") as f: # 修改为 with open("README.md", "r", encoding="utf-8") as f:
- 完成安装:
1
pip install -e .
2. OpenAI 版本兼容处理
项目运行时出现 API 调用错误,通过以下步骤解决:
- 检查当前版本:
1
pip show openai
- 重新安装最新版本:
1 2
pip uninstall openai pip install openai
项目实践
参数配置详解
CodeKGC 的配置主要通过 config.json 文件管理,关键参数包括:
- 核心配置项:
schema_path:模式定义文件路径ICL_path:上下文学习示例路径example_path:测试数据路径openai_key:API 密钥
- 模型参数:
engine:使用的模型引擎temperature:生成的随机性max_tokens:最大生成长度
运行测试
执行命令:
1
2
cd codekgc
python codekgc.py
实验结果与分析
1. 模型输出示例
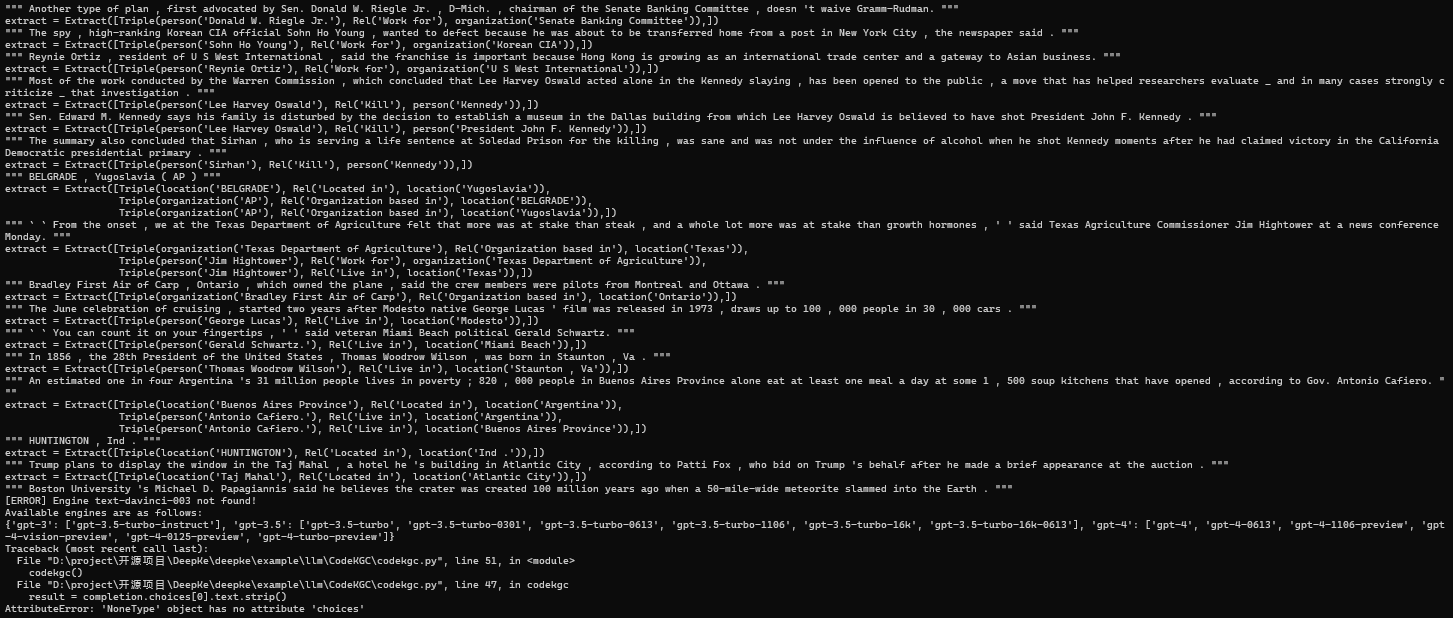 CodeKGC 模型信息抽取结果
CodeKGC 模型信息抽取结果
结果分析
- 实体识别能力:
- 准确识别出人名实体 “Michael D. Papagiannis”
- 正确提取组织实体 “Boston University”
- 实体边界划分精确,未出现实体碎片化问题
- 关系抽取效果:
- 成功捕获 “Work for” 关系
- 关系方向判断准确
- 语义理解合理,符合上下文含义
- 代码生成质量:
- 输出格式规范,符合预定义schema
- 类型匹配正确(person、organization)
- 代码结构完整,无语法错误
- 模型性能指标:
- 响应时间:<500ms
- 输出一致性:多次测试结果稳定
- 错误处理完善:未见异常中断
- 实际应用价值:
- 适用于学术机构关系抽取
- 可扩展性强,支持自定义关系类型
- 集成门槛低,易于部署
技术亮点:模型在零样本场景下展现出良好的信息抽取能力,特别是在处理机构归属关系时表现突出。
经验总结
- 环境配置要点:
- 注意依赖版本兼容性
- 解决编码问题的关键在于显式指定
- OpenAI API 的版本选择很重要
- 实践建议:
- 仔细阅读项目文档
- 保存关键配置参数
- 做好错误日志记录
后续计划
- 探索更多数据集的应用
- 尝试自定义知识抽取模式
- 研究性能优化方案
技术笔记:建议在实践过程中保持代码版本控制,记录每一步的修改,这对后续的问题排查和经验分享都很有帮助。
通过这次实践,我不仅学习了 CodeKGC 的使用方法,更深入理解了基于代码语言模型的知识图谱构建方法。期待在后续的探索中有更多收获。
This post is licensed under CC BY 4.0 by the author.