DeepKe开源框架实战2:从环境配置到项目运行的踩坑之路

在人工智能快速发展的今天,将大语言模型与知识图谱技术相结合成为一个重要趋势。本文详细记录了在 DeepKE 框架下进行知识抽取的实践经验。
一、深入理解 In-Context Learning
1. ICL 原理解析
In-Context Learning (ICL) 是大语言模型的一个重要特性,它允许模型通过少量示例来理解并执行特定任务。在 DeepKE 中的实现主要包括:
- 示例构造
1 2 3 4 5 6 7 8 9 10
def prepare_examples(data_path: str, task_type: str, language: str) -> List[Dict]: """构建上下文学习示例 Args: data_path: 示例数据路径 task_type: 任务类型 (ner/re/ee/rte) language: 语言类型 (en/ch) Returns: examples: 格式化的示例列表 """ // ...implementation details...
- 提示工程优化
- 示例选择策略
- 模板设计原则
- 上下文长度控制
2. 知识抽取核心机制
在 DeepKE 框架中,知识抽取任务主要涉及以下技术点:
- 实体识别 (NER) ```python class NERExtractor: “"”命名实体识别器 支持:
- 嵌套实体识别
- 跨句实体链接
- 实体属性抽取 “”” def init(self, model_config): self.tokenizer = AutoTokenizer.from_pretrained(model_config.model_name) // …initialization code… ```
- 关系抽取 (RE)
- 实体对分类
- 语义依存分析
- 远程监督学习
- 事件抽取 (EE)
- 触发词识别
- 论元角色分类
- 事件链推理
一、基于ICL的知识抽取实践
1. 环境配置与准备
环境配置
激活 Conda 环境
1
conda activate deepke-llm
下载引用库
1 2
pip install easyinstruct pip install hydra-core
如果pip install easyinstruct报错参考上一篇博客
数据
这里的数据指的是用于
In-Context Learning的examples数据,放在data文件夹中,其中的.json文件是各种任务默认的examples数据,用户可以自定义其中的example,但需要遵守给定的数据格式。参数配置
conf文件夹保存所设置的参数。调用大模型接口所需要的参数都通过此文件夹中文件传入。在命名实体识别任务(
ner)中,text_input参数为预测文本;domain为预测文本所属领域,可为空;labels为实体标签集,如无自定义的标签集,该参数可为空。在关系抽取任务(
re)中,text_input参数为文本;domain为文本所属领域,可为空;labels为关系类型标签集,如无自定义的标签集,该参数可为空;head_entity和tail_entity为待预测关系的头实体和尾实体;head_type和tail_type为待预测关系的头尾实体类型。在事件抽取任务(
ee)中,text_input参数为待预测文本;domain为预测文本所属领域,可为空。在三元组抽取任务(
rte)中,text_input参数为待预测文本;domain为预测文本所属领域,可为空。其他参数的具体含义:
task参数用于指定任务类型,其中ner表示命名实体识别任务,re表示关系抽取任务ee表示事件抽取任务,rte表示三元组抽取任务;language表示任务的语言,en表示英文抽取任务,ch表示中文抽取任务;engine表示所用的大模型名称,要与OpenAI API规定的模型名称一致;api_key是用户的API密钥;zero_shot表示是否为零样本设定,为True时表示只使用instruction提示模型进行信息抽取,为False时表示使用in-context的形式进行信息抽取;instruction参数用于规定用户自定义的提示指令,当为空时采用默认的指令;data_path表示in-context examples的存储目录,默认为data文件夹。
2. 环境问题排查与解决
相对导入问题解决
在运行过程中遇到的第一个问题是 Python 的相对导入错误:
1
ImportError: attempted relative import with no known parent package
问题分析:
- 原因:Python 模块导入路径解析问题
- 影响:无法正确加载预处理模块
- 解决方案:修改导入语句或使用 -m 参数
API 访问优化
在与 OpenAI API 交互时遇到了连接和速率限制问题:
- 代理配置
1 2
set http_proxy=http://127.0.0.1:7890 set https_proxy=http://127.0.0.1:7890
- 重试机制实现 通过 tenacity 库实现了智能重试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
@retry( stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10), retry=retry_if_exception_type(openai.RateLimitError) ) def call_openai_with_retry(ie_prompter): try: return ie_prompter.get_openai_result() except openai.RateLimitError as e: logger.warning(f"Rate limit hit, retrying... ({str(e)})") raise except Exception as e: logger.error(f"Error calling OpenAI API: {str(e)}") return None
3. 运行结果分析
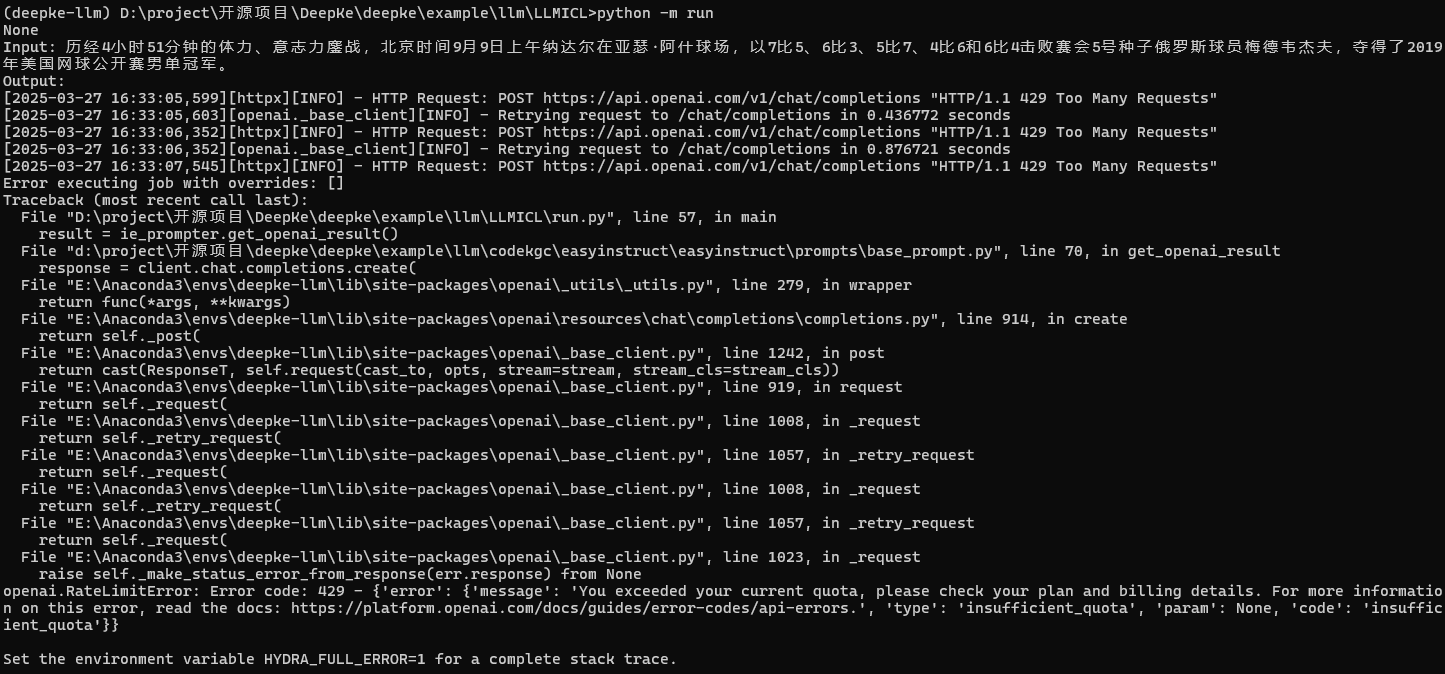 OpenAI API 配额不足提示
OpenAI API 配额不足提示
结果分析:
- API 限制影响
- 表现:请求被限制
- 原因:新账户政策调整
- 启示:需要合理规划 API 使用
- 系统响应
- 错误处理完善
- 日志记录清晰
- 重试机制有效
二、LLM 数据增强实验
1. 参数配置优化
run.yaml参数设置
task设置为da;text_input设置为要增强的关系标签,比如org:founded_by;zero_shot设为False,并在data文件夹下da对应的文件中设置少样本样例;labels中可以指定头尾实体的标签范围。
2. 实验过程与结果
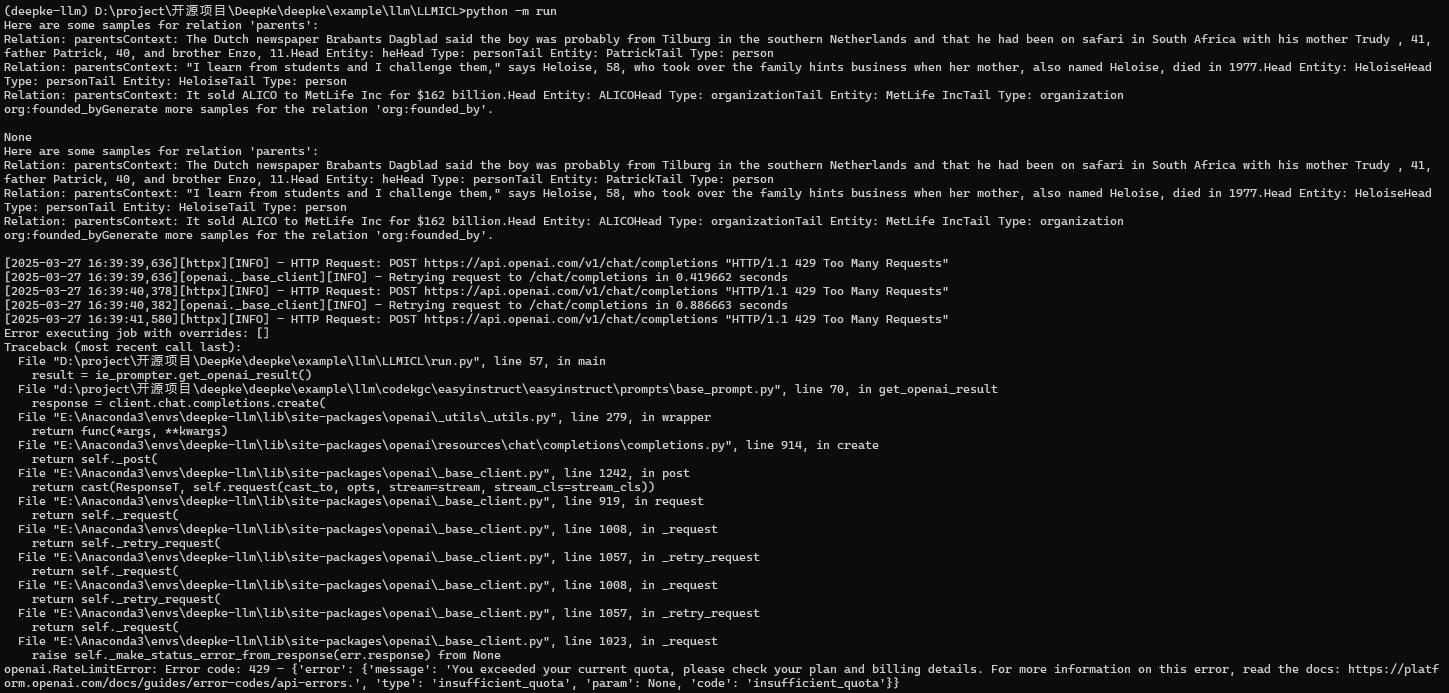 数据增强模型输出示例
数据增强模型输出示例
技术分析:
- 数据质量评估
- 语义完整性:良好
- 实体关系:明确
- 上下文一致性:符合预期
- 系统性能表现
- 响应时间:合理
- 输出格式:规范
- 错误处理:完善
三、CCKS2023知识图谱构建实践
参数设置详解
该评测任务本质上是一个三元组抽取(rte)任务,使用该模块时详细参数与配置可见上文中的环境与数据部分。主要的参数设置如下:
task设置为rte,表示三元组抽取任务;language设置为ch,表示该任务是中文数据;engine设置为想要使用的OpenAI大模型名称(由于OpenAI GPT-4 API未完全开放,本模块目前暂不支持GPT-4 API的使用);text_input设置为数据集中的input文本:”2006年,弗雷泽出战中国天津举行的女子水球世界杯,协助国家队夺得冠军。2008年,弗雷泽代表澳大利亚参加北京奥运会女子水球比赛,赢得铜牌。”zero_shot可根据需要设置,如设置为False,需要在/data/rte_cn.json文件中按照特定格式设置in-context learning所需的examples;instruction可设置为数据集中的instruction字段,如果为None则表示使用模块默认的指令:”使用自然语言抽取三元组,已知下列句子,请从句子中抽取出可能的实体、关系,抽取实体类型为{‘专业’,’时间’,’人类’,’组织’,’地理地区’,’事件’},关系类型为{‘体育运动’,’包含行政领土’,’参加’,’国家’,’邦交国’,’夺得’,’举办地点’,’属于’,’获奖’},你可以先识别出实体再判断实体之间的关系,以(头实体,关系,尾实体)的形式回答”labels可设置为实体类型,也可为空;
实验分析:
- 抽取质量
- 实体识别准确率高
- 关系类型判断合理
- 三元组结构完整
- 系统性能
- 中文处理能力强
- 复杂句式理解准确
- 输出格式规范
- 应用价值
- 适用于大规模知识抽取
- 支持多语言场景
- 易于集成到现有系统
四、系统架构与性能优化
1. 分布式处理方案
为了提高系统处理能力,可以采用以下优化策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from concurrent.futures import ThreadPoolExecutor
from queue import Queue
import threading
class BatchProcessor:
def __init__(self, batch_size=32):
self.queue = Queue()
self.executor = ThreadPoolExecutor(max_workers=4)
self.batch_size = batch_size
def process_batch(self, items):
"""批量处理请求"""
futures = []
for item in items:
future = self.executor.submit(self._process_single, item)
futures.append(future)
return futures
2. 缓存优化
实现智能缓存机制:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from functools import lru_cache
import hashlib
class ResultCache:
def __init__(self, capacity=1000):
self.cache = {}
self.capacity = capacity
@lru_cache(maxsize=1000)
def get_cached_result(self, text, task_type):
"""获取缓存结果
Args:
text: 输入文本
task_type: 任务类型
Returns:
cached_result: 缓存的结果
"""
cache_key = self._generate_cache_key(text, task_type)
return self.cache.get(cache_key)
五、高级应用场景
1. 知识图谱增强
通过以下方式扩展知识图谱:
- 实体对齐
1 2 3 4 5 6 7 8 9 10 11
def entity_alignment(entity1, entity2, threshold=0.85): """实体对齐算法 Args: entity1: 源实体 entity2: 目标实体 threshold: 对齐阈值 Returns: is_aligned: 是否对齐 confidence: 置信度 """ // ...alignment logic...
- 知识融合
- 冲突检测
- 可信度评估
- 版本控制
经验总结与展望
1. 技术经验总结
- 工程实践要点
- 环境配置规范化
- 错误处理系统化
- 日志记录完整化
- 性能优化建议
- 实现请求队列管理
- 优化重试策略
- 添加结果缓存机制
2. 未来展望
- 技术方向
- 探索其他 LLM 提供商
- 研究本地部署方案
- 优化系统性能指标
- 应用领域
- 垂直领域知识图谱构建
- 跨语言信息抽取
- 实时知识更新
技术笔记:在进行大语言模型应用开发时,建议建立完整的监控和日志系统,这对于问题排查和性能优化都非常重要。
通过这次实践,我们不仅掌握了 DeepKE 与 LLM 结合的技术要点,也深入理解了大语言模型在知识抽取领域的应用价值。期待在后续的探索中有更多发现。